AlpaGasus: Training a Better Alpaca with Fewer Data

The name "AlpaGasus" combines two words, Alpaca and Pegasus. The logo is generated by Midjourney.
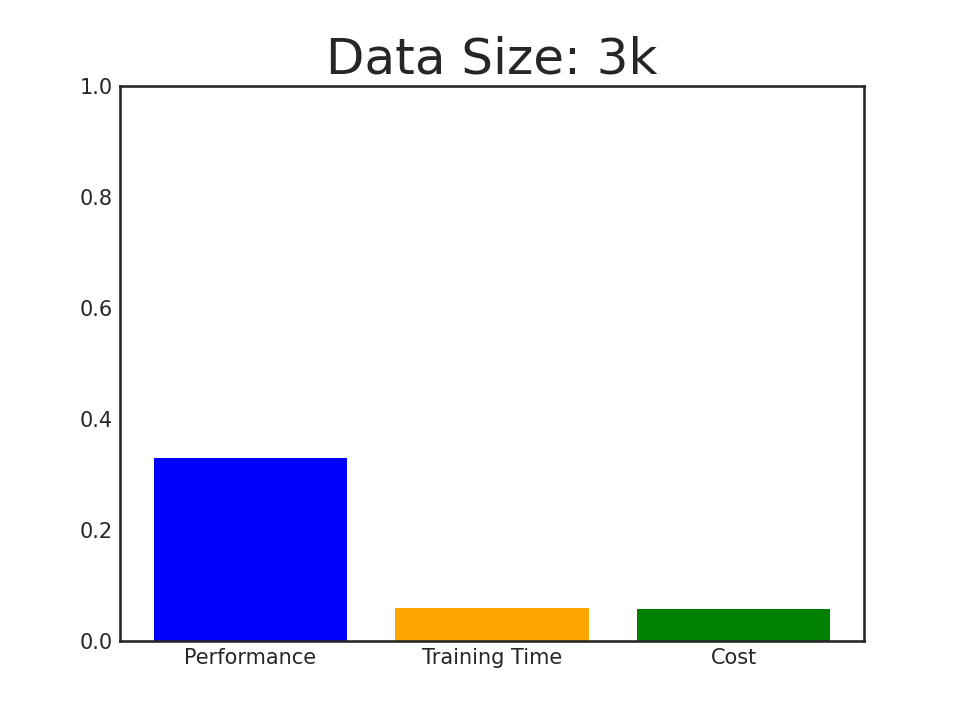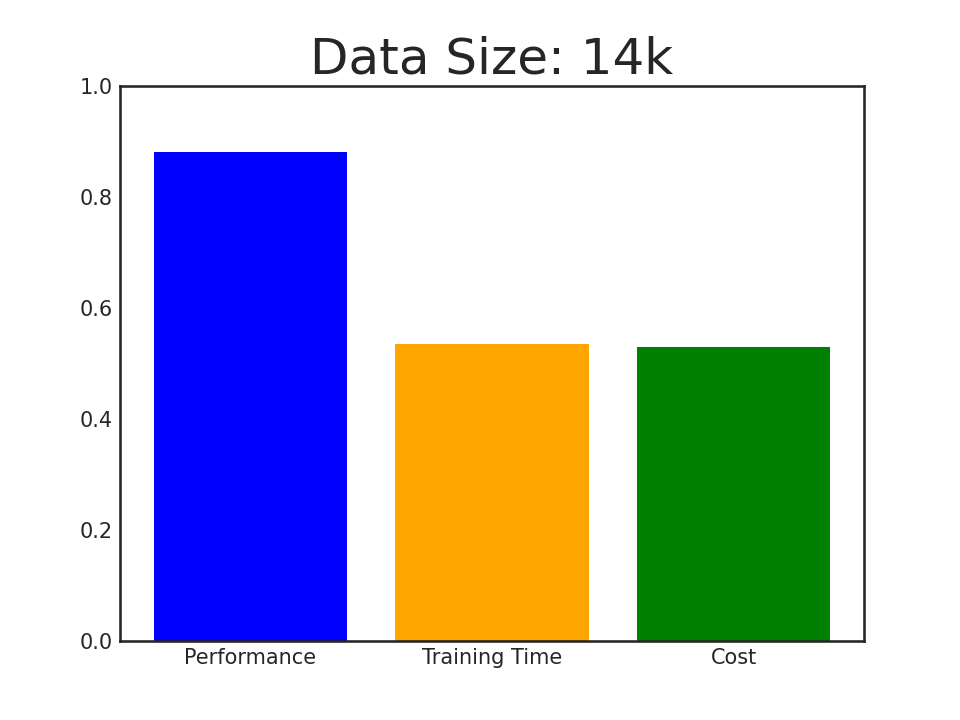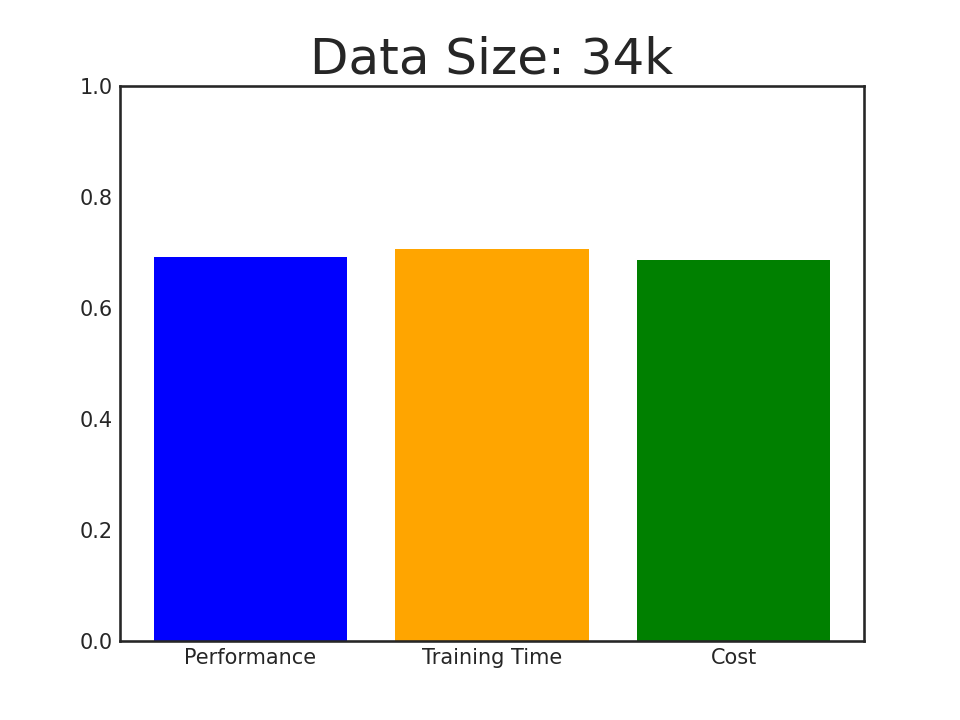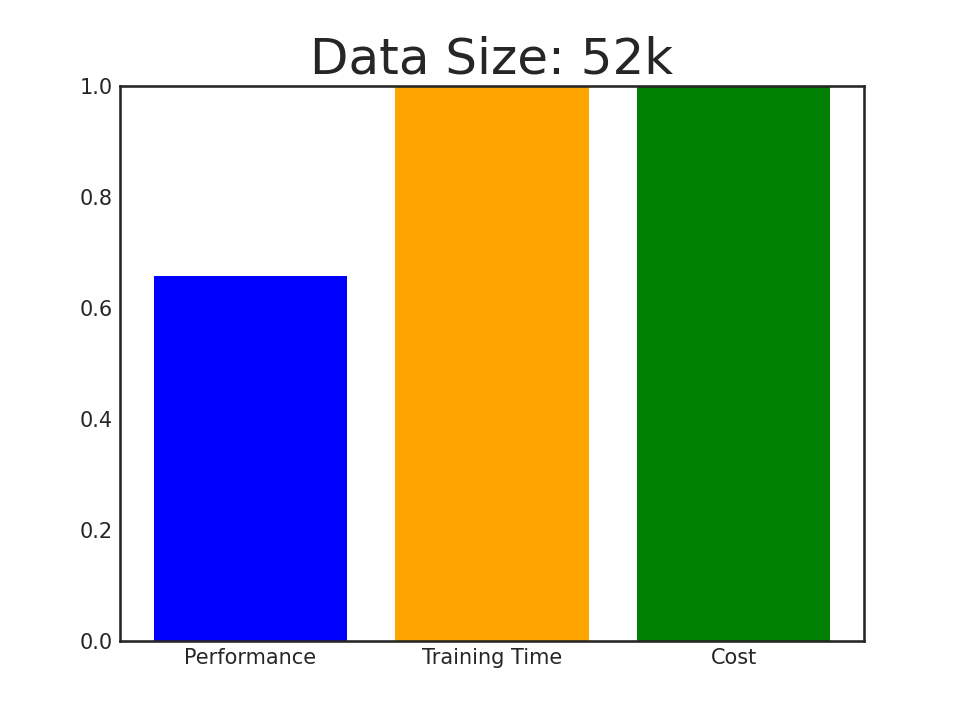
Introducing AlpaGasus: using less data, training faster, and obtaining better performance!
Overview
In this paper, we propose a simple and effective data selection strategy that automatically identifies and removes low-quality data using a strong LLM (e.g., ChatGPT). To this end, we introduce AlpaGasus, which is finetuned on only 9k high-quality data filtered from the 52k Alpaca data. AlpaGasus significantly outperforms the original Alpaca as evaluated by GPT-4 on multiple test sets and its 13B variant could match >90% performance of its teacher LLM (i.e., Text-Davinci-003) on test tasks. It also provides 5.7x faster training, reducing the training time for a 7B variant from 80 minutes (for Alpaca) to 14 minutes.

Performance of AlpaGasus on four test sets when increasing its finetuning data, where the winning score is \( \frac{ \text{#Win} - \text{#Lose}}{\text{#Testset}} + 1 \) with #Testset = #Win + #Tie + #Lose to be the test set size and #win/#tie/#lose to be the number of samples on which \(\text{AlpaGasus}\) wins/draws/loses.
TL;DR: The first automatic framework to filter bad data in the IFT datasets.
Score Distribution

Histogram of Scores. Threshold=4.5
We filter out 9k data from original Alpaca's 52k data.
Main Results
Win-Tie-Lose figures for comparisons of 7B and 13B models instruction-finetuned with different training sets. (Ours: 9k vs. Original Alpaca: 52k)

For other experiment results, please refer to our paper.
Code Release
1. Full-model finetuning(FSDP): thanks for @gpt4life reproducing our results and upload the models to huggingface. (They use Claude as LLM-filter for reproducing so the final results may be different from our paper.)
2. QLoRA: thanks to @gauss5930 and @YooYunS who implemented the QLoRA version of Alpagasus-7B and 13B, which could be run on the customer-level GPUs. please refer to their repo: @Alpagasus2-QLoRA They also show that tuning LLaMA-2 could achieve better performance.
Future Work
Since IFT datasets could be gathered either via crowdsourcing or generated by machines such as GPT4, we will also test our method on the Dolly training set.