|
I am an AI research scientist at Meta Superintelligence Lab, working in a joint exploration team between MSL and TBD labs. I study agents for automating AI researchers and self-imporvement RL, trying to find the path towards AGI. I did my PhD at the Computer Science Department, University of Maryland, College Park. I obtained my bachelor's degree from Zhejiang University. I can be reached at {bob}{my-last-name}@cs.umd.edu. My name in Chinese: 陈力畅 Google Scholar / Twitter / LinkedIn / Github |

|
|
My research interests are in RL and agentic systems, especially in self-evolving coding agent and how we can automate the realistic workflows such as foundational model research, Machine Learning, and Data Analysis. |
|
AI Research Scientist@Meta SuperIntelligence, 2025 - Present, Agents for automating AI researchers. |
|
Intern@Google Deepmind, Meta RL for reasoning & Thinking to Learn.
|

|
|

|

|
|
|
|
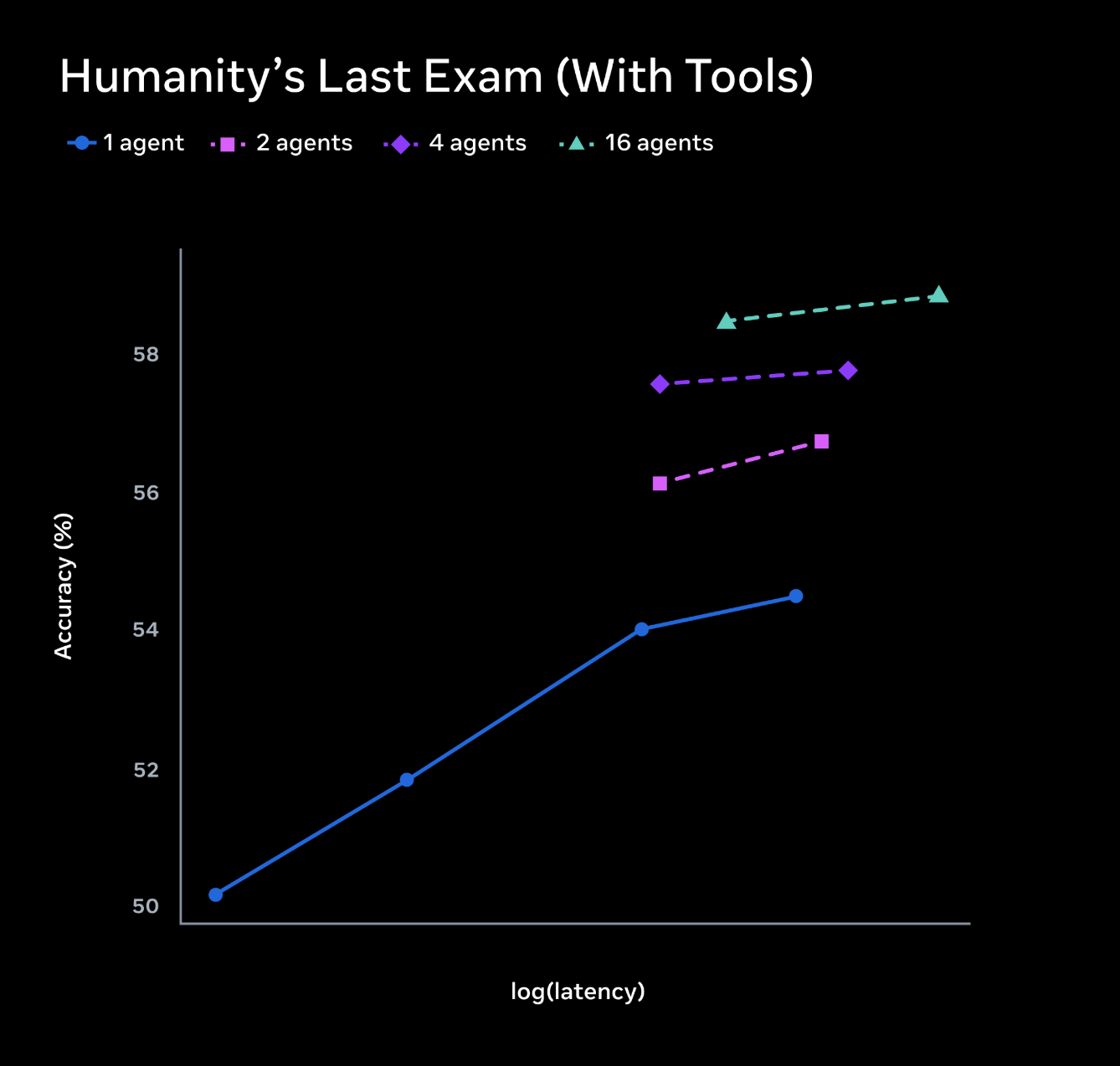
Main Contributor to the Contemplating mode Meta Superintelligence Labs, 2026 |
|
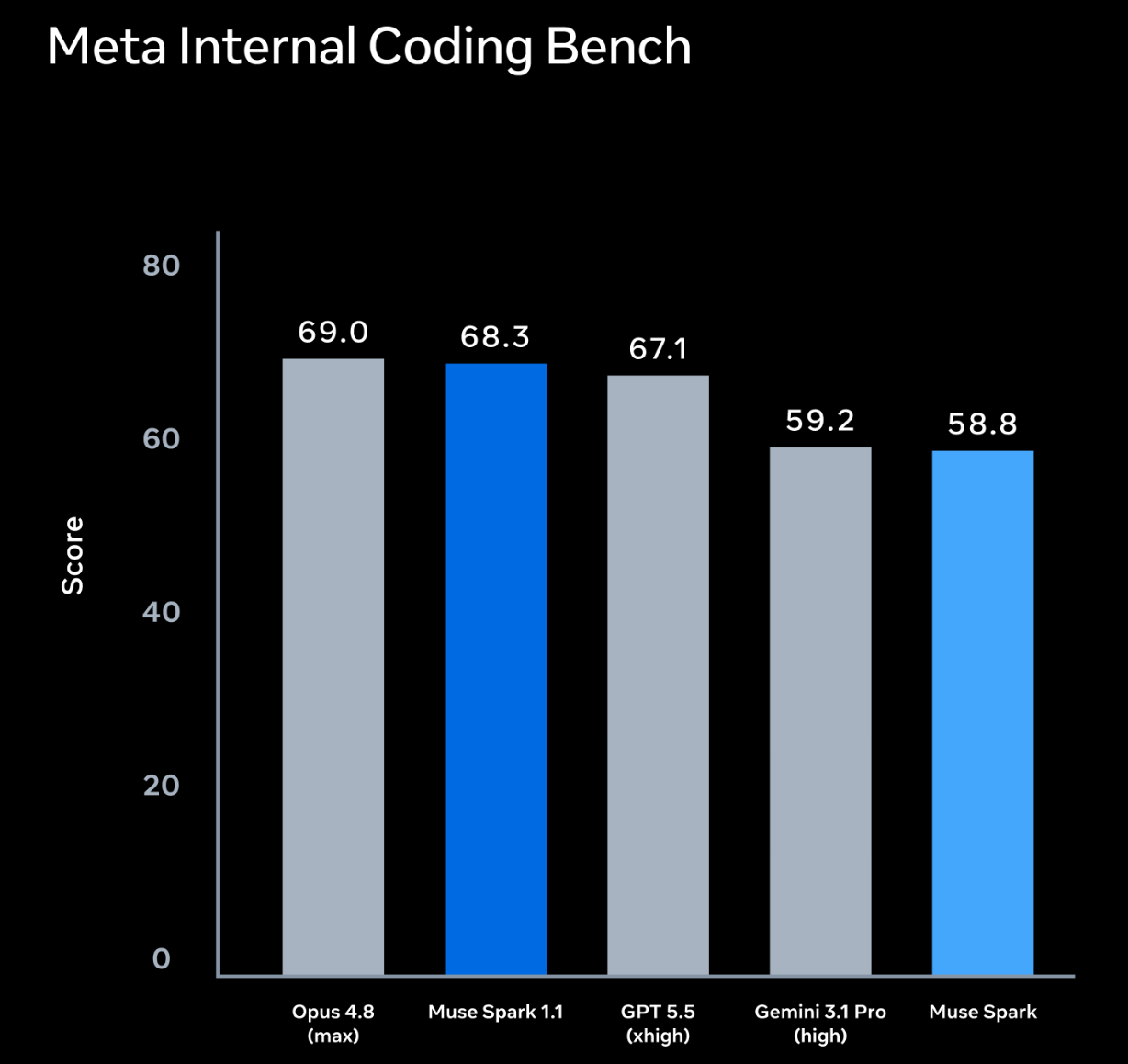
Main Contributor to the SWE agents Meta Superintelligence Labs, 2026 |
|
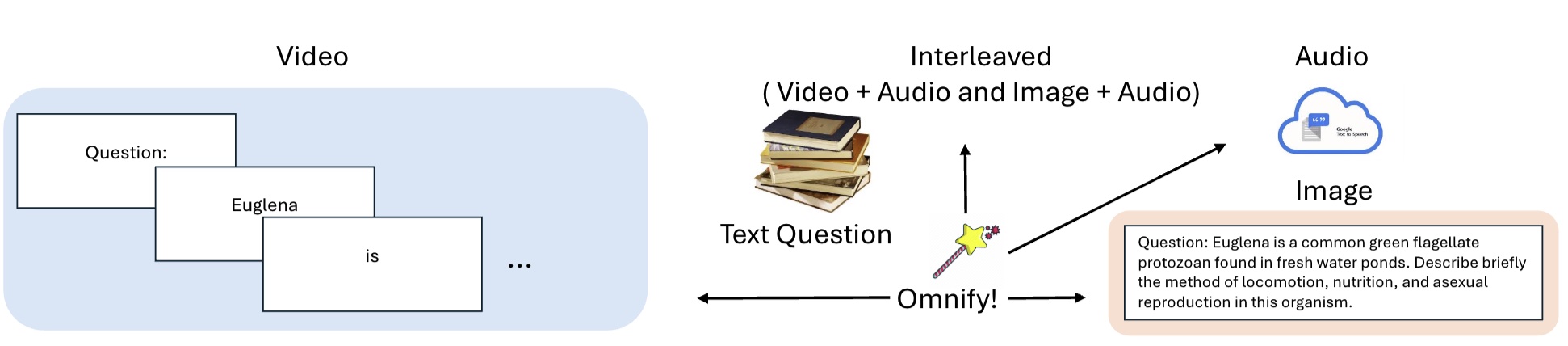
Lichang Chen, Hexiang Hu, Pranav Shyam, Ming-Hsuan Yang, Boqing Gong, et al. Work Done@Google Deepmind, ICLR 2025 |

|
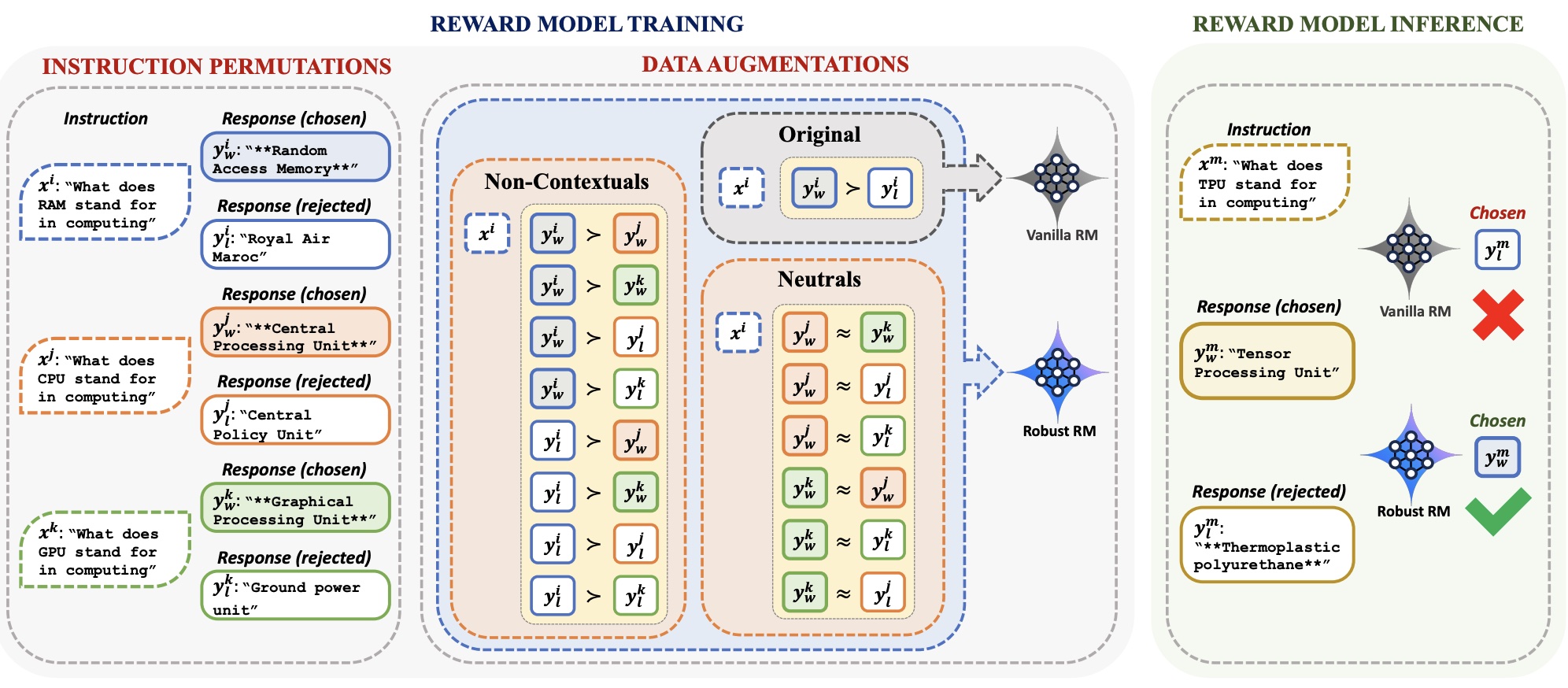
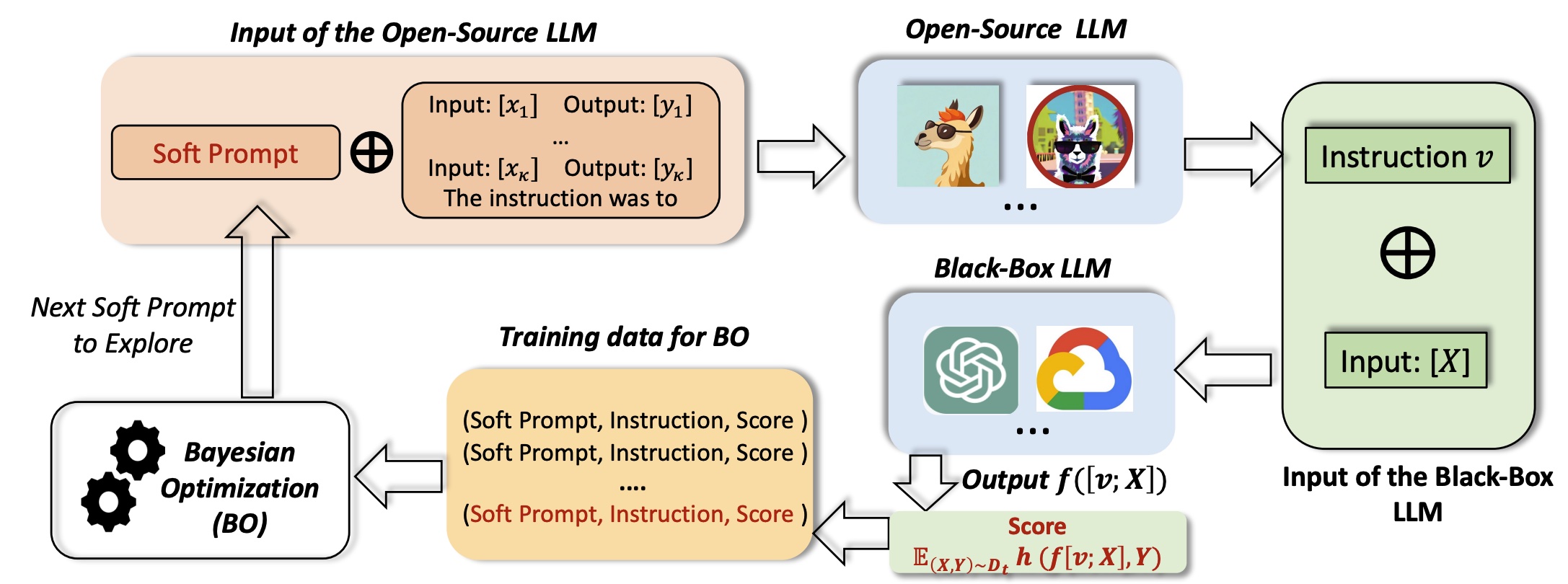
Lichang Chen*, Xuanchang Zhang*, Wei Xiong*, Tianyi Zhou, Heng Huang, Tong Zhang. ACL, 2025 |
|
Tianqi Liu, Wei Xiong, Jie Ren, Lichang Chen, Tianhe Yu, Mohammad Saleh, et al. Work Done@Google Deepmind, ICLR 2025 |
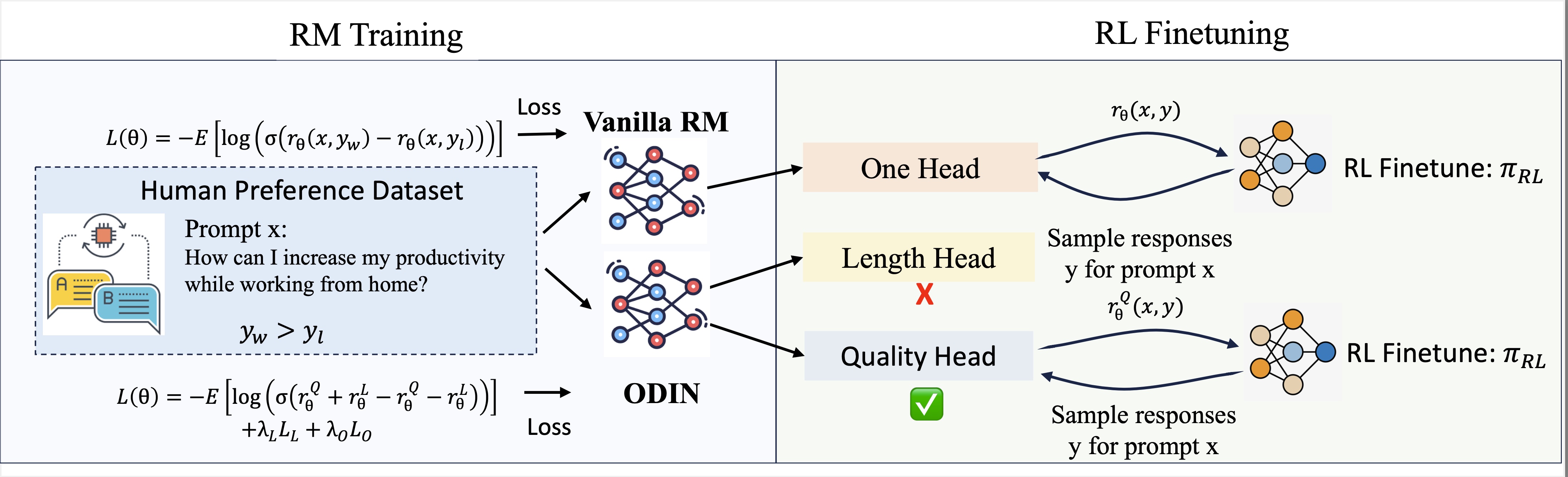
|
Lichang Chen*, Chen Zhu*, Davit Soselio, Tianyi Zhou, Tom Goldstein, Heng Huang, Mohammad Shoeybi, Bryan Catanzaro ICML, 2024. |
|
Lichang Chen*, Jiuhai Chen*, Tom Goldstein, Heng Huang, Tianyi Zhou ICML, 2024 |

|
Lichang Chen*, Shiyang Li*, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, Hongxia Jin ICLR, 2024 |
|
|